

Building an LLM-Powered Agent for Insurance FWA Detection

Executive Summary
- Traditional rule-based Fraud, Waste, and Abuse (FWA) detection systems are insufficient, failing to catch sophisticated fraud due to their lack of context and inability to handle complex, high-dimensionality schemes.
- The proposed solution is a Multi-Agent Architecture (Mixture of Experts), where specialized agents collaborate under a Main Agent to analyze claims with deep domain expertise.
- This agent-based approach provides full-context reasoning, reconstructing the complete claim picture and finding inconsistencies that rules miss (like duplicate therapy or expired medication anomalies).
- The system offers complete explainability, providing analysts with a justified, traceable audit trail of the agent's logic.
- Reliability is ensured by a durable workflow orchestration engine, and LLM hallucinations are mitigated by a multi-layered strategy, including a "Judge Agent".
- The architecture is designed for intelligent scaling, using pre-filtering to reserve agents for complex claims and a cost roadmap focused on model distillation and caching.
Full Article
Insurance fraud isn't just a financial problem, it's a healthcare crisis. Every year, billions of dollars are siphoned away from legitimate care through fraudulent claims, wasteful procedures, and abusive billing practices [1, 2]. Traditional rule-based detection systems catch the obvious cases, but many sophisticated schemes slip through the cracks [3].
We set out to build something different: an AI-powered agent capable of reasoning through complex claims the way a team of human experts would. In this article, we describe how we designed and constructed that system, leveraging years of experience building complex AI models and advanced algorithms for medical fraud claims, and why this approach fundamentally changes what's possible in FWA detection.
1. Why Rules Aren't Enough
Before explaining what we built, it's worth understanding why we needed to build it in the first place.
Today's FWA detection largely relies on static rules: "If X, then flag Y." These rules catch obvious cases like coding errors and false positives, more than actual fraud [3, 4]. The fundamental problem? A rule is an isolated signal. It works well for clear-cut scenarios, but the moment context becomes complex, the approach breaks down.
Consider the dimensionality problem. Real fraud involves multiple interacting factors: patient history, provider behavior, geographic patterns, medication interactions, and timing anomalies. To capture this with rules, you'd need an exponentially growing set of conditions, each requiring manual maintenance. Eventually, someone tells you a scenario is "impossible to detect" because there are too many parameters to consider.
And then there's the data problem. With limited client data and incomplete context, rules miss the forest for the trees. They can't reconstruct the full picture of what's actually happening.
For example, in many cases, costly procedures may appear if the structured data does not include certain attributes that exist only in the original documents. Expiry dates for medications, for instance, are often not extracted into tabular form because the client is not interested in storing them. Yet those expiry dates can still be present on the invoice itself, allowing a system to detect inconsistencies such as medication expiry dates that occur before the invoice date, which would be impossible to catch using tabular data alone.
Similarly, structured diagnosis codes (e.g. ICD codes) may indicate a more severe condition than what is actually supported by the physician’s notes in the document. In other cases, the opposite occurs: a costly procedure may appear unjustified based on the structured data alone, but it becomes reasonable once additional context from clinical notes is considered. Without access to the full document, these discrepancies remain invisible or are misclassified.
We needed a system that reasons, not one that merely matches patterns.
2. The Core Philosophy: A Team of Experts, Not a Single Oracle
Early in the design process, we faced a fundamental choice. We could build one powerful, general-purpose AI model and train it on every known fraud pattern, or we could take a different path. The former assumes the existence of a comprehensive, representative dataset covering all meaningful scenarios. In practice, even if such a dataset did exist, a model trained this way would inevitably learn the past, not the future. Fraud, as an adversarial use case, evolves continuously, new schemes emerge precisely to evade existing detection methods.
This is why we chose the latter approach.
FWA detection isn't a single task. It's a collection of distinct analytical challenges: document classification, medical review, billing validation, geographic analysis, and many more. A single AI trying to master all these domains simultaneously would be a jack of all trades and master of none. That's why we built a roster of specialized agents, each with its own tools and expertise.
Instead, we adopted a Multi-Agent Architecture, often called a "mixture of experts" [5, 6]. Think of it like assembling a specialized investigation team:
- A Main Agent acts as the team lead mimicking everything that we learned from Senior SIU Managers, analyzing incoming claim data and deciding which specialists need to get involved.
- Domain-specific agents, leveraging the different expertise that we built through the years, each bring deep expertise in their area: medical fraud, invoice anomalies, location discrepancies.
- The team works in parallel, then reconvenes to synthesize findings.
Why This Architecture Matters
Accuracy: Each agent is optimized for its domain and equipped with tools tailored to its specific task. Specialization means deeper expertise, each thinks like an expert in its field.
Discovery of Unknown Patterns: Unlike rules that only find what you've already defined, agents can discover patterns you never anticipated. In testing, an agent flagged a batch of medications with reused batch numbers and inconsistent expiration dates, something our data scientists hadn't previously encountered. This is the difference between detecting known fraud and discovering new schemes.
Modularity: We can upgrade, retrain, or add agents independently. When a new fraud pattern emerges, we deploy a specialized agent without touching the rest of the system.
Rapid Iteration: Testing and deploying new detection scenarios takes days, not weeks. We no longer spend months reducing edge cases or compensating for missing data.
3. What Agents Do That Rules Can't
An agent doesn't just check conditions, it reconstructs context and reasons through it.
Full-context reasoning
When an agent analyzes a claim, it assembles the complete picture: diagnosis, prescribed treatments, patient history, provider patterns, geographic data. Then it reasons step by step, just like an experienced analyst would [7]. But faster. And without forgetting anything.
We are uniquely positioned to provide this context. Our system combines document extraction, medical knowledge bases, billing logic, and external references into a single structured claim view. That makes it possible to see details that a typical claim handler would miss or would never have time to manually connect.
Example: Potential duplicate therapy
Two related prescriptions for the same condition are issued on the same day by different providers. On their own, each looks valid. In combination, they can indicate overlapping therapy and unnecessary dispensing.
- Two prescribers issue similar iron therapies for a single patient on the same date.
- The products have equivalent active ingredients and are indicated for the same diagnosis.
- Overlap increases the risk of duplicative supply and avoidable expense.
- If the pharmacy does not flag the overlap, waste is quietly introduced.
Explainability changes everything
Every step of the agent's reasoning is justified and traceable. Analysts can follow the logic like an audit trail [8, 9]. Compare this to a rule that outputs a score with no explanation. For the analysts who review flagged claims, this is transformational: they do not just see that something was flagged, they understand why and know exactly what actions to investigate.
Illustration: Expired medication anomalies
Invoices show medication lots with expiry dates that appear earlier than the invoice dates, implying expired dispensing or inaccurate documentation.
- A set of invoices list expiry dates that predate the billing dates.
- The same lot number appears with conflicting expiry dates across documents.
A single lot should have one expiry. Divergent dates suggest documentation errors or manipulation. Either drugs were dispensed past expiry, or the records are inaccurate. Agents explain each contradiction, so investigators can review exact evidence rather than chase a black-box score.
Robustness against evolving tactics
Fraudsters constantly change their techniques. A rule-based system requires manual updates to catch new schemes. An agent trained to find inconsistencies and logical contradictions can surface anomalies that no one has explicitly programmed for.
We also keep agents up to date. Feedback from investigations becomes new training signals. When an investigator reviews a case, the outcome and rationale are captured so the agent can compare future alerts against validated prior examples. This continuous loop combats model drift and helps the system stay aligned with real-world tactics.
4. The Foundation: Scalable, Durable Execution
Before we could build intelligent agents, we needed reliable infrastructure.
AI-driven analysis involving multiple steps and external data sources is inherently fragile. API calls fail. Services time out. Network connections drop. If we built our system on a naive sequential pipeline, any transient failure would require starting from scratch.
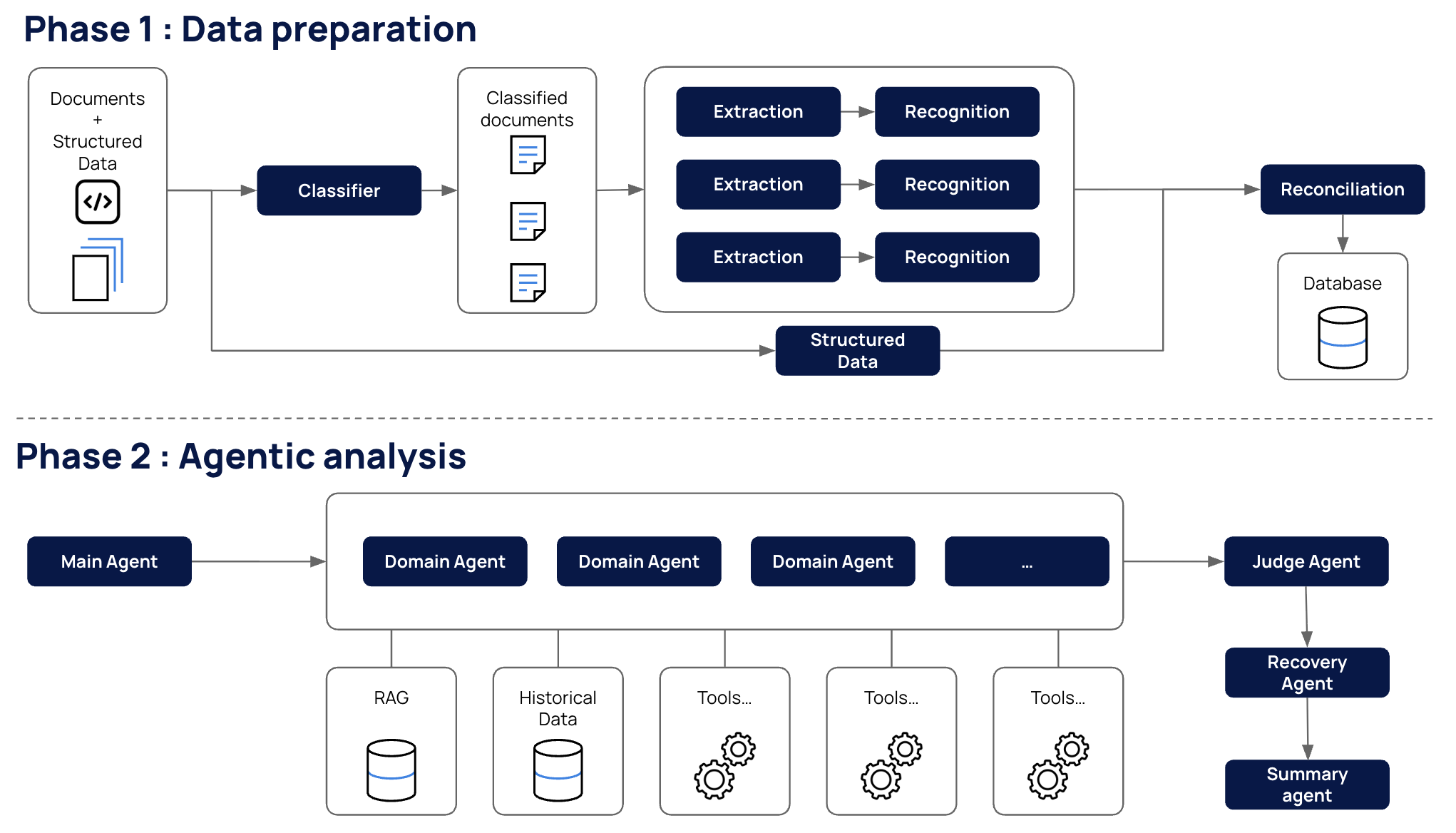
We solved this by constructing the entire process on a durable workflow orchestration engine. This framework acts as the system's backbone, ensuring every analysis runs to completion [10]:
- If an API call fails, the engine automatically retries.
- If a task is interrupted, state is preserved and the process resumes exactly where it left off.
- No data is lost, no work is repeated unnecessarily.
This isn't just an engineering nicety, it's essential for enterprise-grade reliability. When you're processing thousands of claims daily, you can't afford to lose progress.
5. The Pipeline: How a Claim Flows Through the System
Step 1: Data Aggregation
Before any AI touches the claim, we gather everything we might need. A dedicated workflow fetches data from multiple internal sources:
- The policyholder's complete claims history and medical episodes.
- Current policy details and coverage information.
- All specifics of the claim under investigation.
- Associated documents (invoices, prescriptions, medical reports).
This data is assembled into a single, structured package. The key insight here: AI agents work best when they start with complete information. Having agents make numerous uncoordinated data requests introduces latency, inconsistency, and potential for errors.
Step 2: Document Classification and Extraction
Claims come with documents, and those documents are messy. An invoice looks nothing like a lab result, which looks nothing like a prescription.
We built a Document Classification Agent with a detailed understanding of document types. When presented with a document, it analyzes content and layout to determine the category: medical prescription, invoice, lab results, discharge summary, and so on.
Why does this matter? Because the classification determines what happens next. A prescription gets routed to medical validation. An invoice triggers billing analysis. The classifier acts as a traffic controller, ensuring each document reaches the right specialist.
Once classified, documents flow to extraction agents that pull out structured data: line items from invoices, medications from prescriptions, diagnoses from medical reports.
Step 3: Intelligent Routing
With structured data in hand, the Main Agent takes the stage.
This agent analyzes the complete picture (claim data, policy information, episode history, extracted documents) and makes explicit decisions about which specialized agents should be invoked. It also generates the appropriate input parameters for each.
The routing logic is:
- Deterministic and traceable: We can audit exactly why certain agents were called.
- Efficient: Only relevant agents are invoked, avoiding wasted computation.
- Flexible: Routing rules can be refined independently from agent logic, allowing us to adapt to new document types or business constraints without retraining downstream components.
In practice, routing is hybrid, combining document classification outputs (e.g., prescription, invoice, lab report) and rule-based logic over key extracted fields (e.g., presence of drug name, dosage, line items, abnormal values), with optional model-assisted signals in ambiguous cases.
Step 4: Parallel Expert Analysis
Based on routing decisions, the relevant specialized agents execute in parallel. Each agent brings its own domain expertise and a unique set of tools, whether that means cross-referencing against medical knowledge bases, scrutinizing billing patterns, validating geographic consistency, or applying any of the many other analytical capabilities in our arsenal.
To illustrate the breadth: some agents focus on clinical validation (prescriptions, procedures, diagnoses, drug interactions, medical necessity). Others specialize in billing anomalies, invalid codes, pricing irregularities, duplicate charges. Still others validate geography, timing patterns, or document consistency. The router selects from our pool of specialists based on what each claim demands, and that pool grows as we encounter new fraud patterns.
Each agent operates independently with deep domain expertise. Parallel execution means we don't pay a latency penalty for having multiple specialists.
Step 5: Validation and Recovery
Raw signals from specialized agents aren't the final word. We apply a two-stage validation process:
Judge Agent An impartial AI auditor reviews all detected signals. Are they logically sound? Evidence-based? Free from reasoning errors? This step filters out false positives and ensures our findings can withstand scrutiny.
Recovery Agent For validated signals, we calculate the financial impact. This agent maps fraud and waste indicators to specific invoice line items, quantifying potential recoveries.
6. Addressing the Hard Questions
What About Hallucinations?
This is the question everyone asks, and rightly so. LLMs can generate plausible-sounding but incorrect information [11, 12].
Our mitigation strategy is multi-layered:
- Grounded reasoning: Agents reason over actual data, features, patient history, diagnoses, active policies. They don't invent facts; they analyze what's there.
- External verification: Agents have access to external sources and specialized tools to verify their conclusions [13]. A claim about drug interactions is checked against pharmaceutical databases, not just asserted.
- Judge Agent filtering: The judge agent specifically looks for hallucination patterns, suspicious outputs, unsupported claims, logical inconsistencies [14]. Our testing shows we can reliably detect and drop problematic outputs.
- Domain specialization: Each agent handles a narrow scope. A focused agent making claims about its specific domain is far less likely to hallucinate than a general-purpose model trying to do everything.
Is it perfect? No. But the combination of grounding, verification, and filtering brings risk to manageable levels.
How Does It Scale?
We don't run agents on every claim. That would be expensive and unnecessary.
The architecture is designed for intelligent scaling:
- Pre-filtering: Simple signals (our Claim Registration already does this) identify claims worth deeper analysis. The vast majority of claims never need an agent.
- Stateless agents: Each agent is stateless and independent, perfect for Kubernetes, Ray, or serverless deployment. We scale horizontally without coordination overhead.
- Lightweight specialists: Because agents are domain-specific and focused, each one is computationally lightweight. Specialization enables scalability.
What About Costs?
AI inference isn't free, but our roadmap addresses this directly:
- Distillation: We start with powerful frontier LLMs to develop and validate our approach. Over time, we distill successful patterns into smaller, purpose-built models and hybrid rule systems [15].
- Caching: Many claims share common elements, same diagnoses, same active ingredients, same provider patterns. We cache reasoning about these common cases rather than recomputing from scratch.
- Intelligent filtering: With usage data, we learn which claims truly need agent analysis. A significant percentage can be confidently handled by ultra-cheap traditional classifiers (XGBoost, etc.), reserving agent power for complex cases.
7. Looking Ahead
The system we've built represents a new approach to FWA detection, one that combines the reasoning capabilities of modern AI with the reliability demands of enterprise software.
Our next step is to make it more robust and adaptive in production. We are strengthening fallback mechanisms to handle misclassification and low-confidence cases, while expanding the tools available to agents beyond RAG and basic APIs (e.g., structured medical knowledge, claim history, anomaly detection).
We are also actively reducing false positives by leveraging user feedback (overrides, confirmed cases) to recalibrate decisions, refine routing, and introduce stricter validation steps before flagging claims. As the volume of labeled examples grows, we will distill smaller, faster models from stronger agents to improve latency and scalability without sacrificing performance.
In parallel, we are building continuous feedback loops and discovery processes to surface new fraud patterns and guide the creation of new capabilities.
The shift is not just about better models, but about a system that continuously learns and evolves. Fraud schemes will keep changing, and so will we.
8. References
[1] National Health Care Anti-Fraud Association (NHCAA). (2025). The Challenge of Health Care Fraud. https://www.nhcaa.org/
[2] Sadeghi, R., et al. (2025). A global scoping review on the patterns of medical fraud and abuse: integrating data-driven detection, prevention, and legal responses. Frontiers in Public Health. https://pmc.ncbi.nlm.nih.gov/articles/PMC11831774/
[3] Nabrawi, E., & Alanazi, A. (2023). Fraud detection in healthcare insurance claims using machine learning. Risks, 11(9), 160. https://doi.org/10.3390/risks11090160
[4] Villegas-Ortega, J., et al. (2024). Fraud detection in healthcare claims using machine learning: A systematic review. Artificial Intelligence in Medicine, 160, 103061. https://doi.org/10.1016/j.artmed.2024.103061
[5] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
[6] Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., & Zou, J. (2024). Mixture-of-Agents enhances large language model capabilities. arXiv preprint arXiv:2406.04692.
[7] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR). arXiv:2210.03629
[8] Shekhar, S., Leder-Luis, J., & Akoglu, L. (2023). Unsupervised machine learning for explainable health care fraud detection. NBER Working Paper No. 30946. https://doi.org/10.3386/w30946
[9] Hassanin, M., et al. (2025). Fraud detection and explanation in medical claims using GNN architectures. Scientific Reports, 15. https://doi.org/10.1038/s41598-025-22910-6
[10] Temporal Technologies. (2025). Durable Execution meets AI: Why Temporal is ideal for AI agents and Generative AI Apps. https://temporal.io/blog/durable-execution-meets-ai-why-temporal-is-the-perfect-foundation-for-ai
[11] Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1–38. https://doi.org/10.1145/3571730
[12] Tonmoy, S. M. T. I., et al. (2024). A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313.
[13] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems (NeurIPS), 33. arXiv:2005.11401
[14] Zheng, L., Chiang, W. L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems (NeurIPS), 36. arXiv:2306.05685
[15] Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.

